Usb Mass Storage devices usually use the FAT32 filesystem, which it kind of surprising due to how old FAT32 is but it lasts because FAT32 is Win, OSX and Linux compatible and not very difficult to implement in embedded devices.
FAT32 solved some limitations from previous FAT versions as limited file names and file sizes but still uses, as it names implies, a file allocation table to find the cluster that define a file.
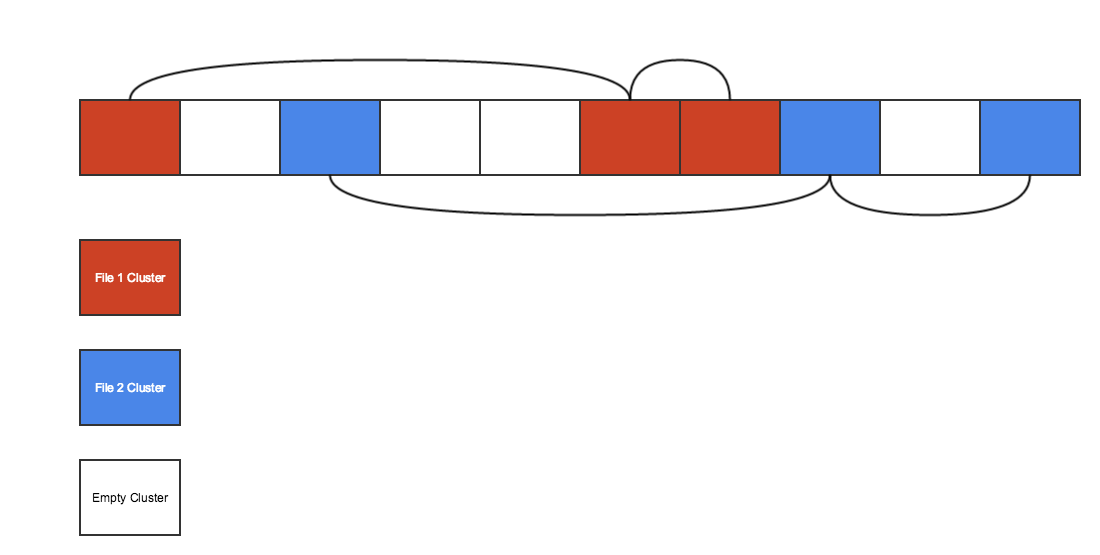
That simplicity comes with a cost, a Θ(n) cost to be exact, because you must traverse the FAT to find a empty cluster. For this reason FAT32 and other linked-list filesystems does not scale very well.
I was aware of this while developing Pincho but it shocked me when I started the first tests. While read operations performs pretty decent, write operations using a naive approach are painfully slow and it gets worse when the USB mass storage device gets crowded with files.
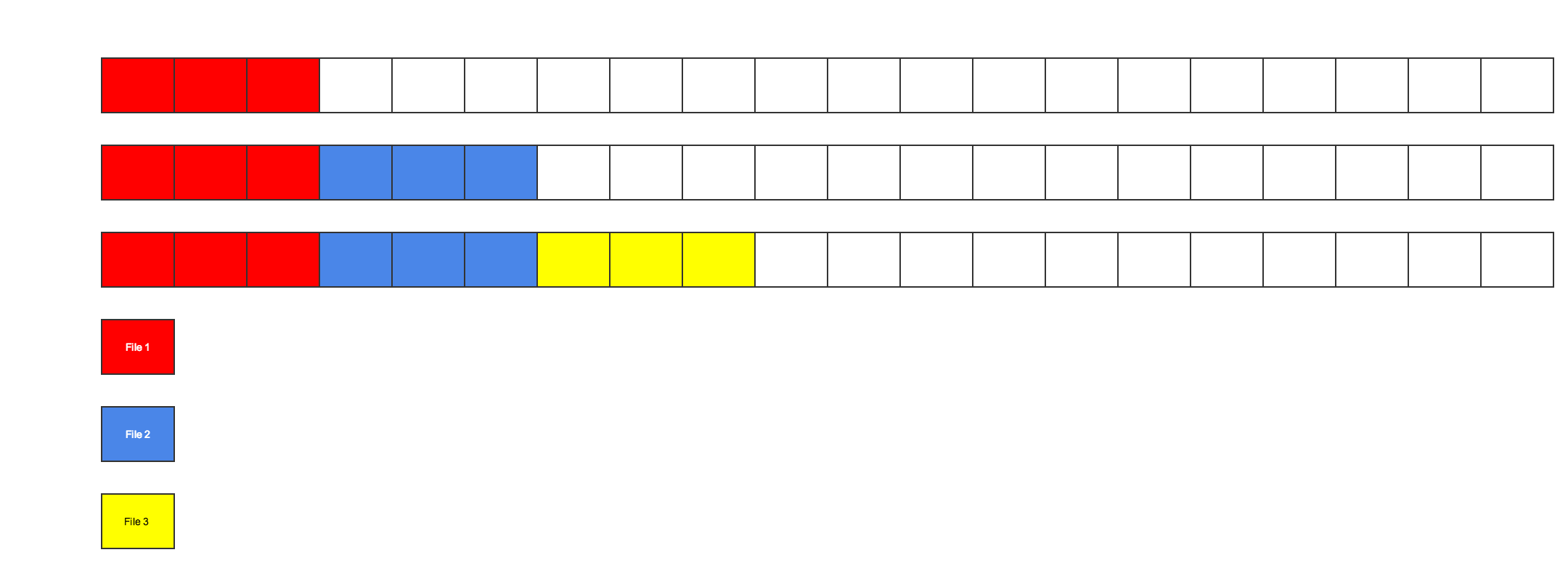
The way to fight with this issue is through caching. Caching is a world itself, with a lot of algorithms and approximations. An aggressive caching will use a lot of memory to store the state of most of the FAT to minimize the I/O operations but Android heap is limited, also consistency must be guaranteed between data in the cache and data in the device and that adds some complexity.
Pincho library is still in kind of experimental state so I would like to try different caching approaches. The first I implemented is probably the simplest, not by far the best, but it gets some improvements. It is simple and it has a small memory footprint.
This implementation assumes correctly that what we want to minimize the number of I/O operations. Storage devices are usually accessed in blocks, called sectors, of 512 bytes addressed by a 32-bit direction called Logic block addressing (LBA). Sectors that compose the FAT can store 128 cluster entries. Those sectors with enough free entries (What is enough must be decided, If sectors with just a few free entries are cached it may not be a good speed improvement) are stored in an Array, that guarantees that an I/O operation on the FAT will return at least some of the free clusters needed to store a file, avoiding traversing the filled parts of the FAT.
I have defined three levels, the low cache just cache enough space to store 100 mb of data, the medium cache try to cache good sectors of half of the cache and the high cache good sectors of the whole FAT. The main difference between these modes is the time needed to perform the cache.
It is an improvement but there is a lot of room for more improvements. For the next releases I have planned to add more sophisticated caching systems.
Happy coding!
